用树莓派 + OpenCV 打造人脸识别技术!
在本指南中,我们将教您如何使用OpenCV和面部识别库(两个出色的开源项目)设置树莓派来检测和识别面部。在这个设置中,所有的数据和处理都将在Pi上本地执行,这意味着您的所有面部和数据都不会离开Pi本身。
像面部识别这样的计算机视觉任务对初学者来说可能有点吓人,但由于许多人的努力,这些任务已经被简化了。我们将从安装所需的库和包开始,然后运行3段代码。首先将使用Pi来拍摄照片,然后我们将使用这些照片作为数据集来训练人脸识别模型,最后我们将运行人脸识别代码本身。
如果你对计算机视觉,目标检测和姿态估计感兴趣,也可以考虑查看以下内容:
在树莓派5上使用YOLO进行物体和动物识别-入门指南
在树莓派5上开启YOLO姿态估计识别之旅!
如何在树莓派 AI HAT+上进行YOLO目标检测?
如何在树莓派 AI HAT+上进行YOLO姿态估计?
让我们开始吧!
目录:
所需材料
硬件组装
安装树莓派操作系统
设置虚拟环境并安装库
拍照并训练模型
运行人脸识别
硬件控制及后续步骤
致谢
代码下载
附录:代码解析
所需材料
要跟随本指南操作,您需要:
树莓派5 - 当使用基于150张图像训练的模型时,我们发现它大约需要1.3GB的RAM。因此,2GB的树莓派可能也能用,但4GB或8GB的型号会更稳妥。本指南也适用于树莓派4,但性能会慢一倍。
树莓派摄像头 - 我们使用的是摄像头模块V3
转接线 - 如果您使用的是树莓派5,它配备的是不同尺寸的CSI摄像头线,而您的摄像头可能配备的是较旧的较粗的线,因此值得仔细检查一下。摄像头模块V3肯定需要一条转接线
散热方案 - 本项目处理量较大,因此需要适当的散热方法。对于我们的树莓派5,我们使用的是主动散热器。
电源
Micro SD卡 - 至少16GB容量
显示器和Micro-HDMI转HDMI线
鼠标和键盘
*所需物品可以直接联系我们进行购买。
硬件组装
在硬件组装方面,这里相当简单。将线缆较粗的一端连接到摄像头,较细的一端连接到树莓派5。这些连接器上有一个标签 - 将其抬起,然后将线缆插入插槽。确保线缆放置整齐且方正,然后将标签推回原位以固定线缆。

请注意,这些连接器只能以一个方向插入,且它们可能比较脆弱,因此请避免过度弯曲(稍微弯曲一点没问题)。
安装Bookworm操作系统
首先,我们需要将树莓派操作系统安装到Micro SD卡上。使用树莓派成像工具,选择树莓派5作为设备,选择Raspberry Pi OS(64位)作为操作系统,并选择您的microSD卡作为存储设备。
注意:将树莓派操作系统安装到MicroSD卡上将会清除卡上的所有数据。
此过程可能需要几分钟时间来下载操作系统并安装。安装完成后,将其插入树莓派并启动。您的树莓派将进行首次安装,请确保将其连接到互联网。
设置虚拟环境并安装库
随着2023年Bookworm操作系统的推出,我们现在需要使用虚拟环境(或venv)。这些只是隔离的虚拟空间,我们可以使用它们来运行项目,而不会破坏树莓派操作系统的其余部分和我们的包 - 换句话说,我们可以在这里随心所欲地操作,而不会损坏树莓派操作系统的其余部分。这是一个需要学习的额外部分,但它非常简单。
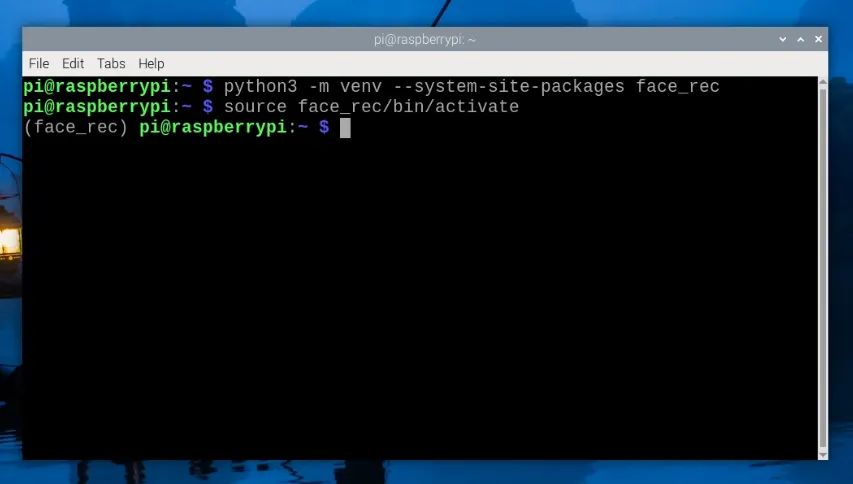
要创建虚拟环境,请打开一个新的终端窗口并输入:
python3 -m venv--system-site-packagesface_rec
这将创建一个名为“face_rec”的新虚拟环境。您可以在home/pi下找到这个虚拟环境的文件夹,它将被命名为“face_rec”。
创建venv后,通过输入以下命令进入它:
sourceface_rec/bin/activate
执行此操作后,您将在绿色文本的左侧看到虚拟环境的名称 - 这意味着我们正在其中正确工作。如果您需要重新进入此环境(例如,如果您关闭了终端窗口,您将退出环境),只需再次输入上面的source命令即可。
现在,我们正在虚拟环境中工作,可以开始安装所需的包了。首先,我们将通过输入以下命令来确保我们的包列表和树莓派是最新的:
sudo aptupdatesudo aptfull-upgrade
然后输入以下命令安装OpenCV:
pipinstall opencv-python
我们还将安装一个我们需要的工具Imutils:
pipinstall imutils
以及一个名为cmake的工具(在提示时按y键):
sudoapt install cmake
然后我们将安装人脸识别库:
pipinstall face-recognition
此安装过程可能需要10到30分钟,因此在此期间请喝杯茶休息一下。
我们还有一件事要做,那就是设置Thonny以使用我们刚刚创建的虚拟环境。Thonny是我们将运行所有代码的程序,我们需要让它从同一个venv中运行,以便它可以访问我们安装的库。
首次打开Thonny时,它可能处于简化模式,您将在右上角看到“切换到常规模式”。如果存在此选项,请点击它并关闭Thonny以重新启动。
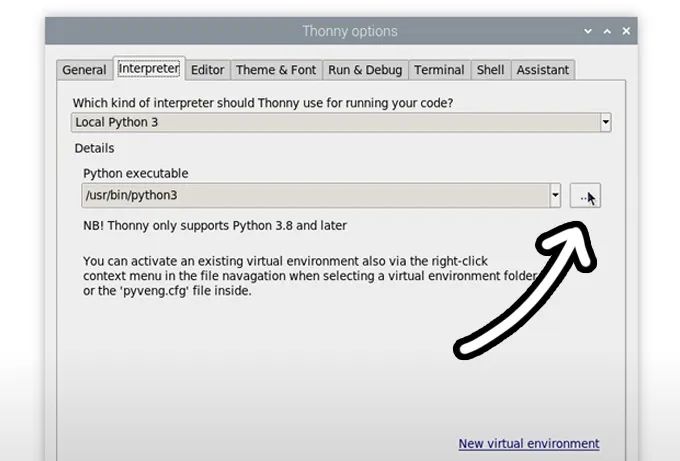
现在,通过选择“运行”>“配置解释器”进入解释器选项菜单。在Python可执行文件选项下,有一个带有三个点的按钮。选择它并导航到我们刚刚创建的虚拟环境中的Python可执行文件。

它位于home/pi/face_rec/bin下,在此文件中,您需要选择名为“python3”的文件。点击确定,您现在将在此venv中工作。
无论何时打开Thonny,它现在都将自动在此环境中运行。您可以通过从同一解释器选项菜单中的Python可执行文件下的下拉菜单中选择它来更改您正在使用的环境。如果您希望退出虚拟环境,请选择“bin/python3”选项。
拍照并训练模型
在开始识别人脸之前,我们需要使用我们希望它识别的人脸来训练模型。首先下载项目文件夹,其中包含运行此项目所需的所有内容。解压并将其放置在易于访问的位置(我们只是将其放在了桌面上)。
在此文件夹中,您将看到我们将使用的三个Python脚本以及一个名为dataset的文件夹。这是我们将用我们希望训练模型的图像填充的文件夹。在Thonny中打开名为image_capture.py的Python脚本 - 您可能需要右键单击并选择Thonny,因为它通常不是默认的Python编辑器。我们不会详细剖析这段代码的工作原理,但我们只需要知道它会拍照并将它们放置在我们需要的正确文件结构中。
在脚本的顶部,您将看到以下行:
# Change this to the name of the person you're photographingPERSON_NAME="John Smith"
当您拍摄某人的面部照片时,这将是分配给该人的名字。请注意,它是区分大小写的,因此John Smith和john smith将是两个人。这里的一个好做法可能是只使用小写字母,以免意外训练同一个人两次。
因此,请继续将其设置为您要训练的第一个人名字,然后点击绿色播放按钮运行它。将弹出一个新窗口显示摄像头画面。调整好位置后按空格键拍照!您可以在此窗口中拍摄任意数量的照片,完成后按“Q”键退出。
选择用于训练模型的照片数量将取决于您的项目。对于大多数应用来说,一张清晰的人脸正对摄像头且光线良好的照片通常就足够了,但再多几张不同角度的人脸照片也无妨。
如果您现在查看dataset文件夹,您将看到此过程已创建了一个以代码开头几行中设置的人名为名称的新文件夹,并且此文件夹内还将包含在此过程中拍摄的所有图像。这就是我们需要训练模型的结构 - 一个包含我们希望识别的人脸名称或ID的文件夹,以及我们希望使用的图像。如果您想使用现有的照片,可以在dataset中创建一个文件夹,将文件夹名称设置为这将识别的人,然后将照片放入其中。
一旦您拥有了所有希望识别的人的照片文件,请在thonny中打开名为model_training.py的脚本。如果您运行此脚本,它将使用所有这些照片来训练我们将在下一步中使用的模型,并且您可以在shell中看到此过程的实时进度。根据您训练它的图像数量,此过程可能需要几秒到几分钟的时间。
训练完成后,您将看到一个完成消息,并且它将创建一个名为“encodings.pickle”的文件 - 这是我们训练好的模型。
运行人脸识别
现在,我们终于准备好运行人脸识别了。在Thonny中打开facial_recognition.py脚本并运行它。几秒钟后,将出现摄像头画面,如果一切正常,它应该能够通过在人脸周围绘制一个框并标注名字来识别人脸。它只能检测到您训练过的人脸,如果它检测到一个不在数据集中的人脸,它将只是将其标记为“未知”。您还可以在右上角看到帧处理速度(FPS)。
您还应该发现它相当准确,即使对于移动和模糊的对象也是如此 - 摇摇头看看它是否仍然能识别您。戴上一副太阳镜,它应该仍然能够识别您。不过,也有一些方法可以欺骗这个系统,如果您将头倾斜超过45度,它可能根本无法识别您,如果您部分遮挡面部,它也将难以检测到您。

我们可以在代码中调整两个变量来增加FPS或处理能力,它们是摄像头的输入分辨率和一个在处理摄像头画面时改变分辨率的缩放器。
在代码的开头部分,您将找到以特定分辨率初始化摄像头的行。默认情况下,它是1920 x 1080像素,我们可以将其设置为几乎任何大小,只要它不超过摄像头的功能范围即可。
picam2.configure(picam2.create_preview_configuration(main={"format": 'XRGB8888',"size": (1920,1080)}))
再往下一点,您将找到一个名为“cv_scaler”的变量。这是一个将摄像头分辨率从我们初始化时的分辨率进行缩放的变量。这个数字必须是一个整数 - 因此不能有小数点。
cv_scaler=4# this has to be a whole number
我们输入到facial_recognition库的分辨率会影响其性能,我们可以调整这两个变量来改变分辨率,因此让我们快速看一下如何首先使用这两个变量来改变分辨率。代码获取摄像头的分辨率并将其除以cv_scaler。以下是一些示例:
如果分辨率设置为1920x1080,且cv_scaler = 10,则处理后的分辨率将为192x108
如果分辨率设置为1920x1080,且cv_scaler = 4,则处理后的分辨率将为480x270
如果分辨率设置为480x270且cv_scaler = 1,则处理后的分辨率将为480x270
请注意,在后两个示例中,处理分辨率为480x270,虽然它们将提供相同的FPS和处理能力,但最后一个的预览窗口将较小且分辨率较低,因为那是我们初始化摄像头画面的大小。最好将您的分辨率设置为较大的尺寸,如1920x1080或1280x720,并更改cv_scaler来降低分辨率。
现在我们知道如何降低分辨率了,让我们看看对性能的影响。下图展示了两种不同分辨率的处理情况。两者都将摄像头初始化为1920x1080,但左图的cv_scaler = 1,结果为0.5 FPS,而右图的cv_scaler = 10,结果约为5 FPS。图像中还显示了它们能够识别人脸的最大距离,左图是从我们大型工作室房间的另一端,而右图只有约一米远。这可能只是心理作用,但我们认为较高的分辨率也可能更准确地捕捉到模糊的对象 - 但差别不大。

硬件控制及后续步骤
到目前为止,我们的设置可以识别人脸、在其周围绘制一个框并标注名字。让我们更进一步,使用名为facial_recognition_hardware.py的脚本对其做些其他事情。此脚本有一些额外的添加,允许我们控制树莓派的GPIO引脚。在脚本的顶部,您将找到一个授权名字列表,当检测到这些名字时,将打开树莓派的14号引脚:
authorized_names= ["john","alice","bob"] # Replace with your actual names
如果您希望向此列表添加或更改名字,请将名字放在括号中并用逗号分隔。请注意,这也是区分大小写的,如果您将所有训练名字都保持小写,请在此处也保持这样做。
在process_frame函数中,我们有以下代码段:
# Control the GPIO pin based on face detection ifauthorized_face_detected: output.on() # TurnonPin else: output.off() # TurnoffPin
这是这个新脚本的核心部分,如果检测到授权人脸,它将打开14号引脚,如果没有检测到人脸,它将关闭该引脚。如果您想在此之外做其他事情,这是您可以添加代码的地方。
在视频指南中,我们连接了一个由电磁阀驱动的门锁和一个继电器,设置了授权名字列表,并在识别人脸时伪“解锁了门”。您还会注意到另一个添加,即我们在授权名单上的人脸下方添加了文字,说明此人是授权的。

虽然这是一个具体的示例,但它可以修改为执行几乎任何任务,因为我们有一个简单的结构 - 如果检测到人脸,则执行某操作,否则执行其他操作。我们可以使用此逻辑来控制一组RGB LED灯,或控制一个伺服电机,或打开一个电机。(另外,如果您想学习如何将电磁阀连接到树莓派,我们有相关指南)
它也不一定非要控制硬件,我们可以选择发送电子邮件,或通过蓝牙发送通知,或任何其他基于软件的自动化。虽然我们没有明确的指南介绍这些,但您应该可以将我们的演示脚本粘贴到像ChatGPT或Claude这样的LLM中,并让它们帮助您编写所需的代码。
致谢
像这样的项目之所以成为可能,要归功于众多人员将开源项目带给大众所做出的不可思议的工作。我们主要想向OpenCV和人脸识别库团队表示衷心的感谢,感谢他们创建了这些项目。我们还要感谢Caroline Dunn开发了大量利用pickle模型的代码。
代码下载
您可以在此zip文件中找到本指南中运行的所有脚本。
https://core-electronics.com.au/attachments/uploads/facial-recognition-updated.zip
附录:代码解析
对于那些希望了解这段代码内部工作原理的人来说,让我们快速浏览一下并看看幕后发生了什么。这并不是了解发生了什么的必要条件,但对于那些想要了解的人来说只是一个额外的内容。
与往常一样,我们的代码从导入所需的库开始,包括我们之前安装的OpenCV和人脸识别库:
importface_recognitionimportcv2importnumpyasnpfrompicamera2importPicamera2importtimeimportpickle
然后我们加载我们创建的pickle模型并将其解包为faces和names。
print("[INFO] loading encodings...")withopen("encodings.pickle","rb")asf: data= pickle.loads(f.read())known_face_encodings =data["encodings"]known_face_names =data["names"]
使用Picamera 2,我们然后以指定的分辨率初始化摄像头:
picam2= Picamera2()picam2.configure(picam2.create_preview_configuration(main={"format": 'XRGB8888',"size": (1920,1080)}))picam2.start()
然后我们初始化一堆将在代码其余部分使用的变量。这是我们可以更改cv_scaler的地方:
cv_scaler=4#
face_locations= []face_encodings= []face_names= []frame_count=0start_time= time.time()fps=0
接下来,我们创建第一个函数,该函数接收一帧并从中获取识别数据。它首先使用cv_scaler将我们输入的帧缩小到较低的分辨率。然后,根据库的需要将其从BGR转换为RGB:
defprocess_frame(frame): globalface_locations, face_encodings, face_names
# Resize the frame using cv_scaler to increase performance (less pixels processed, less time spent) resized_frame= cv2.resize(frame, (0,0), fx=(1/cv_scaler), fy=(1/cv_scaler))
# Convert the image from BGR to RGB colour space, the facial recognition library uses RGB, OpenCV uses BGR rgb_resized_frame= cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
然后我们将缩小后的帧输入到人脸识别库中,并获取人脸的位置和编码。
face_locations= face_recognition.face_locations(rgb_resized_frame) face_encodings= face_recognition.face_encodings(rgb_resized_frame, face_locations, model='large')
之后,我们使用一个for循环遍历图像中的所有人脸,并查看编码是否与我们训练模型中的任何编码匹配。
face_names=[] forface_encoding in face_encodings: # See if the face is a match for the known face(s) matches= face_recognition.compare_faces(known_face_encodings, face_encoding) name="Unknown"
# Use the known face with the smallest distance to the new face face_distances= face_recognition.face_distance(known_face_encodings, face_encoding) best_match_index= np.argmin(face_distances) ifmatches[best_match_index]: name= known_face_names[best_match_index] face_names.append(name)
returnframe
然后我们创建另一个函数,该函数将接收帧并在其周围绘制框,以及用识别出的名字标注它。for循环意味着它将遍历所有识别出的人脸。它使用顶部、右侧、底部和左侧坐标(我们在上一个函数中通过face_locations找到的)在识别出的人脸周围绘制一个框。但在使用它之前,我们必须按cv_scaler进行缩放,否则它不会在我们的摄像头预览上绘制在正确的位置(处理是在缩小后的帧上进行的,因此我们必须将坐标放大以匹配我们的摄像头预览):
defdraw_results(frame): # Display the results for(top, right, bottom, left), nameinzip(face_locations, face_names): # Scale back up face locations since the frame we detected in was scaled top *= cv_scaler right *= cv_scaler bottom *= cv_scaler left *= cv_scaler
然后我们使用OpenCV提供的工具来实际绘制这些东西。我们首先在人脸周围绘制一个蓝色的空矩形,线宽为3,然后在这个框上绘制一个实心矩形,最后将名字放在这个实心框上。
# Draw a box around the face cv2.rectangle(frame, (left, top), (right, bottom), (244,42,3),3)
# Draw a label with a name below the face cv2.rectangle(frame, (left -3, top -35), (right+3, top), (244,42,3), cv2.FILLED) font= cv2.FONT_HERSHEY_DUPLEX cv2.putText(frame, name, (left +6, top -6), font,1.0, (255,255,255),1)
returnframe
然后我们创建最后一个函数来计算我们的FPS。在它的最后,它将当前时间存储在一个变量中,下次我们调用它时,它将比较该时间与新时间以计算出经过的时间,并据此计算FPS。
# Draw a box around the face cv2.rectangle(frame, (left, top), (right, bottom), (244,42,3),3)
# Draw a label with a name below the face cv2.rectangle(frame, (left -3, top -35), (right+3, top), (244,42,3), cv2.FILLED) font= cv2.FONT_HERSHEY_DUPLEX cv2.putText(frame, name, (left +6, top -6), font,1.0, (255,255,255),1)
returnframe
随着我们的函数布局完成,我们终于准备好进入我们无限重复的while True循环了。这首先使用Picamera2从摄像头捕获一帧,然后将该帧输入到我们的process_frame函数中,该函数输出所有识别出的人脸及其位置。然后我们将其输入到display_frame中,该函数获取人脸位置和识别出的人脸,并将它们绘制在一帧上。这个display_frame变量就是我们稍后将告诉树莓派显示的帧:
whileTrue: # Capture a frame from camera frame = picam2.capture_array()
# Process the frame with the function processed_frame = process_frame(frame)
# Get the text and boxes to be drawn based on the processed frame display_frame = draw_results(processed_frame)
之后,我们调用calculate_fps函数来计算我们的FPS,然后我们使用更多OpenCV工具将FPS计数器附加到显示帧上,然后我们在预览窗口中显示它!
# Calculate and update FPS current_fps= calculate_fps()
# Attach FPS counter to the text and boxes cv2.putText(display_frame, f"FPS: {current_fps:.1f}", (display_frame.shape[1] -150,30), cv2.FONT_HERSHEY_SIMPLEX,1, (0,255,0),2)
# Display everything over the video feed. cv2.imshow('Video', display_frame)
最后,在循环结束时,我们检查是否按下了“q”键。如果按下了,我们将退出这个while True循环并运行最后一段代码,该代码将安全地停止摄像头并关闭摄像头预览窗口:
# Break the loop and stop the script if 'q' is pressed ifcv2.waitKey(1) == ord("q"): break# By breaking the loop we run this code here which closes everythingcv2.destroyAllWindows()picam2.stop()
原文地址:
https://core-electronics.com.au/guides/raspberry-pi/face-recognition-with-raspberry-pi-and-opencv/
- 魏牌V9X上市期待这么久终于上市了,34.98万元起!
- 苏宁易购拟1元底价“甩卖”家乐福中国主体:持续推进非主营业务瘦身
- 浙商策略:双创冲高回落大盘调整 短线或震荡、中线暂无忧
- 全线跳水!超15万人爆仓!霍尔木兹海峡,大消息
- 韩国股市重挫 启动卖方“熔断机制”!
- 注意风险!5月以来超110只ST股下跌 3股已腰斩
- 单笔订单总额超全年营收!一字涨停后,华秦科技回应:今年干不完
- 稀缺!高研发+高成长的优质次新股 仅10只(附名单)
- 335亿元市值上市公司 第六大股东是演员张凌赫?公开信息显示非同一人 公司回应
- 国信策略:A股日历效应还有效吗?
- 云南锗业十倍股 磷化铟概念龙头爆发(附名单)
- 一家精神病院炒股成前十大股东 力压高盛 曾套现273万元 当地回应
- 【风口研报】国内首个大规模算电协同绿电项目投运 绿电板块有望迎增长新纪元
- 官司打赢了,钱却没到账?永辉超市亏损25亿元后又陷36亿元追债困局
- 东阳光拿到金额最高190亿算力大单 东莞首富抢占AI产业风口
- 五家上市险企一季度新业务价值普涨 是否已进入新一轮修复周期?